More than 1,000,000 data lakes run on AWS. Amazon S3 is the best place to build data lakes because of its unmatched durability, availability, scalability, security, compliance, and audit capabilities.RedShift is comparable to a cloud data warehouse. It also has in-built tools to deliver real-time and predictive analysis. In contrast, S3 is primarily a storage platform that's similar to a data lake. Businesses can use it as a destination at the end of their data pipeline.Azure Data Lake is the competitor to AWS Cloud Formation. As with AWS, Azure Data Lake is centered around its storage capacity, with Azure blob storage being the equivalent to Amazon S3 storage.
What is the advantage of Azure Data Lake : Data lakes provide organizations with a single repository for all their data, both structured and unstructured. Organizations can replicate, move, and store their data from multiple sources in a data lake, data warehouse, or database using data integration.
Why is S3 better
All-time Availability: Amazon S3 gives every user, its service access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of websites. S3 Standard is designed for 99.99% availability and Standard – IA is designed for 99.9% availability.
Why use S3 over database : Amazon S3 provides the most durable storage in the cloud and industry leading availability. Based on its unique architecture, S3 is designed to provide 99.999999999% (11 nines) data durability and 99.99% availability by default, backed by the strongest SLAs in the cloud.
AWS S3 is a key-value store, one of the major categories of NoSQL databases used for accumulating voluminous, mutating, unstructured, or semistructured data. You can even use S3 as a data destination and move data from Salesforce and other systems into the platform. With Integrate. io's Amazon S3 ETL tools, you can: Perform ReverseETL, ELT (extract, load, transform), and CDC (change data capture/data replication).
Why use a data lake
Data lakes allow you to import any amount of data that can come in real-time. Data is collected from multiple sources, and moved into the data lake in its original format. This process allows you to scale to data of any size, while saving time of defining data structures, schema, and transformations.
Intended audience.
Prerequisites.
Step 1: Create a data analyst user.
Step 2: Create a connection in AWS Glue.
Step 3: Create an Amazon S3 bucket for the data lake.
Step 4: Register an Amazon S3 path.
Step 5: Grant data location permissions.
Step 6: Create a database in the Data Catalog.
Since a data lake has no predefined schema, it retains all of the original attributes of the data collected, making it best suited for storing data that doesn't have an intended use case yet. They tend to be more vulnerable to the development of data silos (data that is not accessible to all departments or teams in the company), which can then become data swamps (no metadata, unorganised). Containing sensitive data can raise security concerns.
Which is an advantage of using S3 : AWS S3 Benefits
Scalability: S3 charges you only for what resources you actually use, and there are no hidden fees or overage charges. You can scale your storage resources to easily meet your organization's ever-changing demands. Availability: S3 offers 99.99 percent availability of objects.
What are the benefits of using S3 instead : Benefits of using S3
Budget-friendly. As we discussed earlier, Amazon provides services based on a pay-as-you-go model.
High scalability. Scalability is the measure to increase or decrease the resource as per need.
Durability.
High availability.
Security.
Easy to manage.
Is S3 cheaper than database
AWS S3 offers a highly cost-effective solution for data storage compared to traditional databases. Backup and restore is the easiest and usually the preferred method for the initial load of the target database. In this method, you create a full backup of your self-managed SQL Server database, transfer it to an Amazon S3 bucket, and restore it to your Amazon RDS for SQL Server instance.For performance, S3 provides high-speed data retrieval, and DynamoDB offers quick and predictable performance with low latency. In terms of pricing, while both use pay-as-you-go, S3 charges for storage and the number of requests, and DynamoDB charges for read and write request units and storage.
Why not use S3 as a database : While S3 provides high durability and availability, it is not optimized for low latency and high I/O performance, which are essential requirements for a primary database. If we need to store structured data, we should consider using a relational database such as Amazon RDS or a NoSQL database such as Amazon DynamoDB.


![Kladsko-5-malý-Karlův-Most[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Kladsko-5-maly-Karluv-Most1-1024x692-250x120.jpg)
![Stubai[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Stubai1-250x120.jpg)


Antwort Why use S3 as data lake? Weitere Antworten – Why S3 for data lake
More than 1,000,000 data lakes run on AWS. Amazon S3 is the best place to build data lakes because of its unmatched durability, availability, scalability, security, compliance, and audit capabilities.RedShift is comparable to a cloud data warehouse. It also has in-built tools to deliver real-time and predictive analysis. In contrast, S3 is primarily a storage platform that's similar to a data lake. Businesses can use it as a destination at the end of their data pipeline.Azure Data Lake is the competitor to AWS Cloud Formation. As with AWS, Azure Data Lake is centered around its storage capacity, with Azure blob storage being the equivalent to Amazon S3 storage.
What is the advantage of Azure Data Lake : Data lakes provide organizations with a single repository for all their data, both structured and unstructured. Organizations can replicate, move, and store their data from multiple sources in a data lake, data warehouse, or database using data integration.
Why is S3 better
All-time Availability: Amazon S3 gives every user, its service access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of websites. S3 Standard is designed for 99.99% availability and Standard – IA is designed for 99.9% availability.
Why use S3 over database : Amazon S3 provides the most durable storage in the cloud and industry leading availability. Based on its unique architecture, S3 is designed to provide 99.999999999% (11 nines) data durability and 99.99% availability by default, backed by the strongest SLAs in the cloud.
AWS S3 is a key-value store, one of the major categories of NoSQL databases used for accumulating voluminous, mutating, unstructured, or semistructured data.
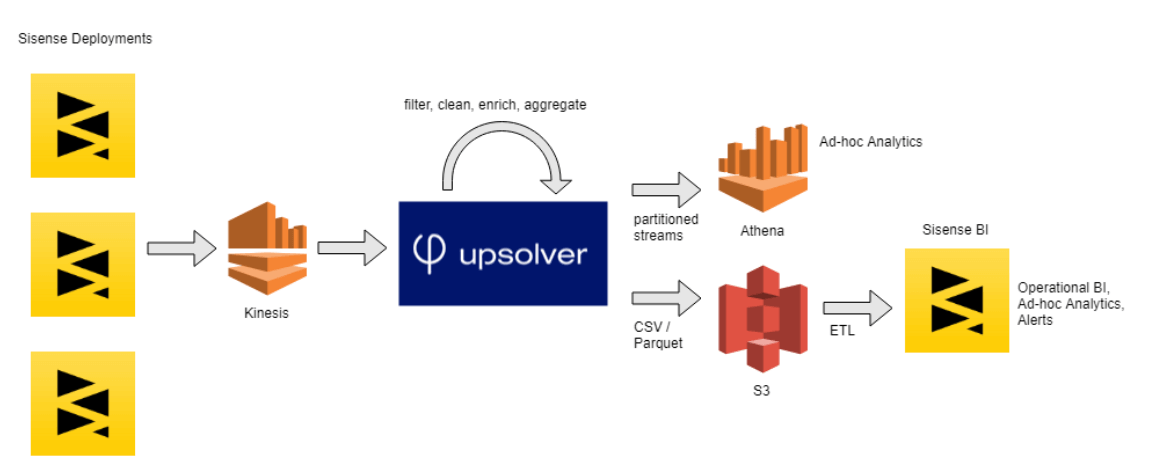
You can even use S3 as a data destination and move data from Salesforce and other systems into the platform. With Integrate. io's Amazon S3 ETL tools, you can: Perform ReverseETL, ELT (extract, load, transform), and CDC (change data capture/data replication).
Why use a data lake
Data lakes allow you to import any amount of data that can come in real-time. Data is collected from multiple sources, and moved into the data lake in its original format. This process allows you to scale to data of any size, while saving time of defining data structures, schema, and transformations.
Since a data lake has no predefined schema, it retains all of the original attributes of the data collected, making it best suited for storing data that doesn't have an intended use case yet.
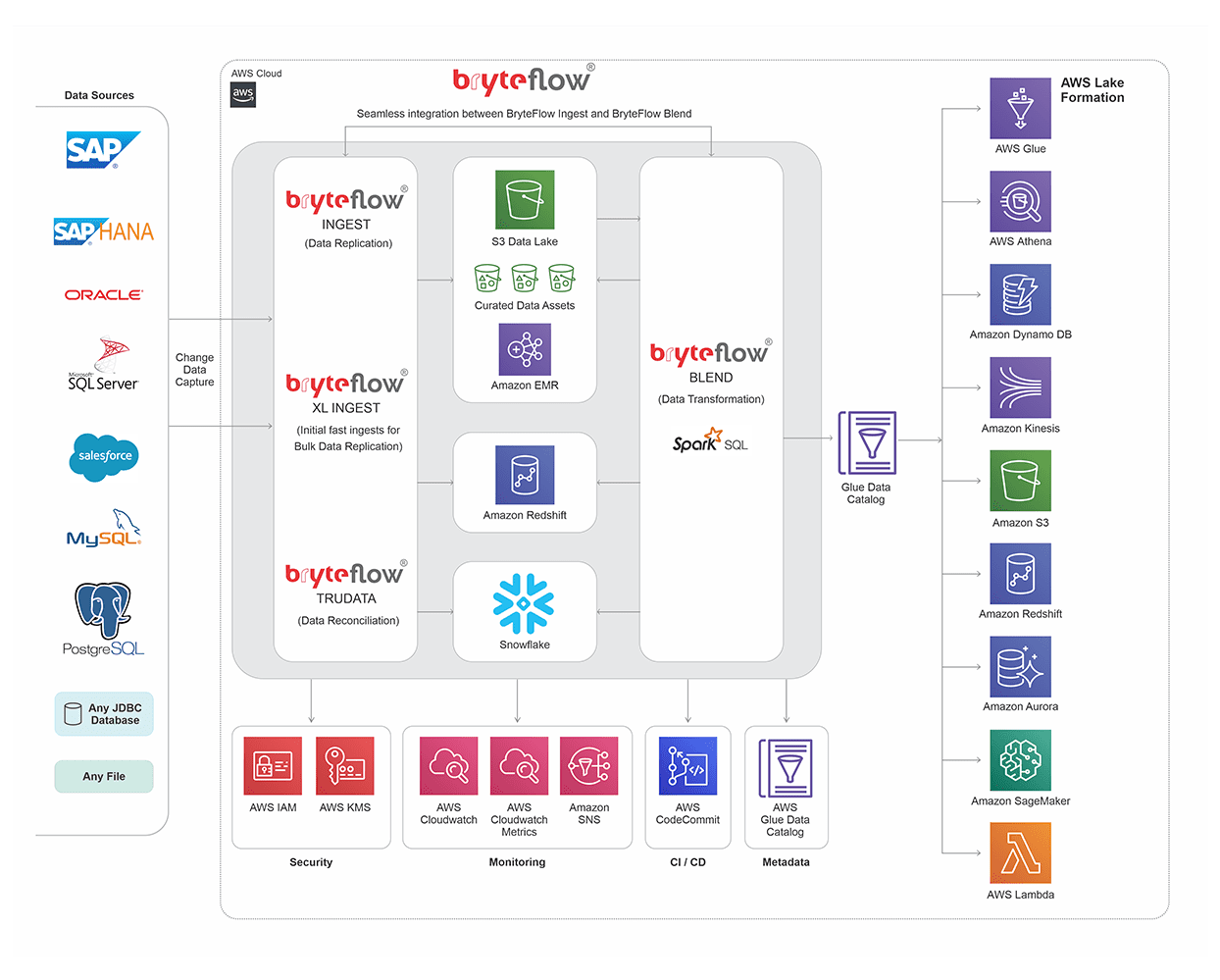
They tend to be more vulnerable to the development of data silos (data that is not accessible to all departments or teams in the company), which can then become data swamps (no metadata, unorganised). Containing sensitive data can raise security concerns.
Which is an advantage of using S3 : AWS S3 Benefits
Scalability: S3 charges you only for what resources you actually use, and there are no hidden fees or overage charges. You can scale your storage resources to easily meet your organization's ever-changing demands. Availability: S3 offers 99.99 percent availability of objects.
What are the benefits of using S3 instead : Benefits of using S3
Is S3 cheaper than database
AWS S3 offers a highly cost-effective solution for data storage compared to traditional databases.
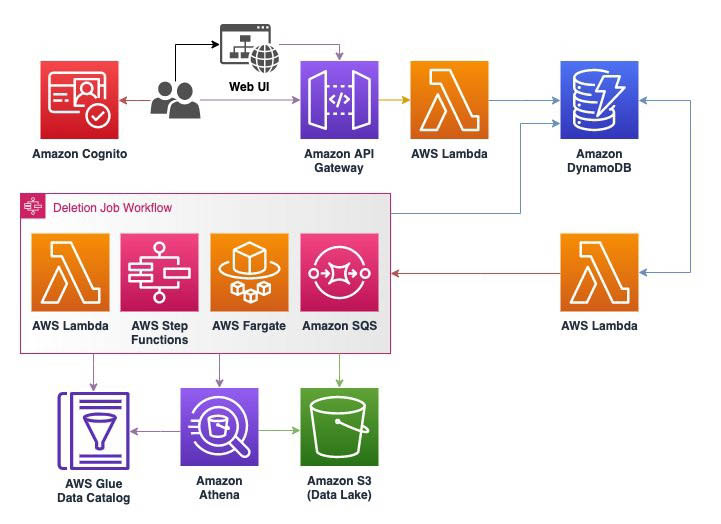
Backup and restore is the easiest and usually the preferred method for the initial load of the target database. In this method, you create a full backup of your self-managed SQL Server database, transfer it to an Amazon S3 bucket, and restore it to your Amazon RDS for SQL Server instance.For performance, S3 provides high-speed data retrieval, and DynamoDB offers quick and predictable performance with low latency. In terms of pricing, while both use pay-as-you-go, S3 charges for storage and the number of requests, and DynamoDB charges for read and write request units and storage.
Why not use S3 as a database : While S3 provides high durability and availability, it is not optimized for low latency and high I/O performance, which are essential requirements for a primary database. If we need to store structured data, we should consider using a relational database such as Amazon RDS or a NoSQL database such as Amazon DynamoDB.