GPU architecture offers unmatched computational speed and efficiency, making it the backbone of many AI advancements. The foundational support of GPU architecture allows AI to tackle complex algorithms and vast datasets, accelerating the pace of innovation and enabling more sophisticated, real-time applications.5 Best GPUs for AI and Deep Learning in 2024
Top 1. NVIDIA A100. The NVIDIA A100 is an excellent GPU for deep learning.
Top 2. NVIDIA RTX A6000. The NVIDIA RTX A6000 is a powerful GPU that is well-suited for deep learning applications.
Top 3. NVIDIA RTX 4090.
Top 4. NVIDIA A40.
Top 5. NVIDIA V100.
Nvidia's other strength is CUDA, a software platform that allows customers to fine tune the performance of its processors. Nvidia has been investing in this software since the mid-2000s, and has long encouraged developers to use it to build and test AI applications. This has made CUDA the de facto industry standard.
Why GPU is best for AI : While the GPU handles more difficult mathematical and geometric computations. This means GPU can provide superior performance for AI training and inference while also benefiting from a wide range of accelerated computing workloads.
Which GPU does OpenAI use
Many prominent AI companies, including OpenAI, have relied on Nvidia's GPUs to provide the immense computational power that's required to train large language models (LLMs).
Which GPU is best for AI : 5 Best GPUs for AI and Deep Learning in 2024
Top 1. NVIDIA A100. The NVIDIA A100 is an excellent GPU for deep learning.
Top 2. NVIDIA RTX A6000. The NVIDIA RTX A6000 is a powerful GPU that is well-suited for deep learning applications.
Top 3. NVIDIA RTX 4090.
Top 4. NVIDIA A40.
Top 5. NVIDIA V100.
So, even if other big tech players continue their chip development efforts, Nvidia is likely to remain the top AI chip player for quite some time. Japanese investment bank Mizuho estimates that Nvidia could sell $280 billion worth of AI chips in 2027 as it projects the overall market hitting $400 billion. Nvidia V100 GPUs
Since GPT-3 is a very large model with 175 billion parameters, it requires very high resources in training. According to this article it takes around 1,024 Nvidia V100 GPUs to train the model, and it costs around $4.6M and 34 days to train the GPT-3 model.
Is ChatGPT using Nvidia
It was developed by NVIDIA and Microsoft Azure, in collaboration with OpenAI, to host ChatGPT and other large language models (LLMs) at any scale.Once Nvidia realised that its accelerators were highly efficient at training AI models, it focused on optimising them for that market. Its chips have kept pace with ever more complex AI models: in the decade to 2023 Nvidia increased the speed of its computations 1,000-fold.700 gigabytes
GPT-3 requires 700 gigabytes of GPU RAM. I'm looking at my cheapest computer components retailer listing a 48 gigabyte GPU at $5k. So to run the previous generation of GPT would cost me about $70k right now. Many prominent AI companies, including OpenAI, have relied on Nvidia's GPUs to provide the immense computational power that's required to train large language models (LLMs). (OpenAI CEO Sam Altman has teased the idea of starting his own GPU manufacturing operation, citing scarcity concerns.)
Does ChatGPT use CUDA : In real-world applications like ChatGPT, deep learning frameworks like PyTorch handle the intricacies of CUDA, making it accessible to developers without needing to write CUDA code directly.
How many GPUs does GPT 4 use : For inference, GPT-4: Runs on clusters of 128 A100 GPUs. Leverages multiple forms of parallelism to distribute processing.
How many GPUs do I need for GPT-3
Achieving GPT3 finetuning with as few as 2 NVIDIA A100 GPUs
By solving the challenges revealed above, we have successfully finetuned a GPT3-sized BLOOMZ model with 176B parameters (termed as OCRL-BLOOM) with as few as 2 NVIDIA A100 GPUs (40GB) to achieve a finetuning speed of 3.9 tokens/sec/GPU. Training 100 Trillion Parameters
The creation of GPT-3 was a marvelous feat of engineering. The training was done on 1024 GPUs, took 34 days, and cost $4.6M in compute alone [1]. Training a 100T parameter model on the same data, using 10000 GPUs, would take 53 Years.The company's graphics processing units (GPUs) and other chips have experienced skyrocketing demand because those products are especially well suited to make demanding applications like ChatGPT run, and ChatGPT's own success has showcased the power of Nvidia's GPUs.
Does Tesla use CUDA : Its products began using GPUs from the G80 series, and have continued to accompany the release of new chips. They are programmable using the CUDA or OpenCL APIs.


![Kladsko-5-malý-Karlův-Most[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Kladsko-5-maly-Karluv-Most1-1024x692-250x120.jpg)
![Stubai[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Stubai1-250x120.jpg)


Antwort Why is CUDA so good for AI? Weitere Antworten – What is the use of GPU in AI
GPU architecture offers unmatched computational speed and efficiency, making it the backbone of many AI advancements. The foundational support of GPU architecture allows AI to tackle complex algorithms and vast datasets, accelerating the pace of innovation and enabling more sophisticated, real-time applications.5 Best GPUs for AI and Deep Learning in 2024
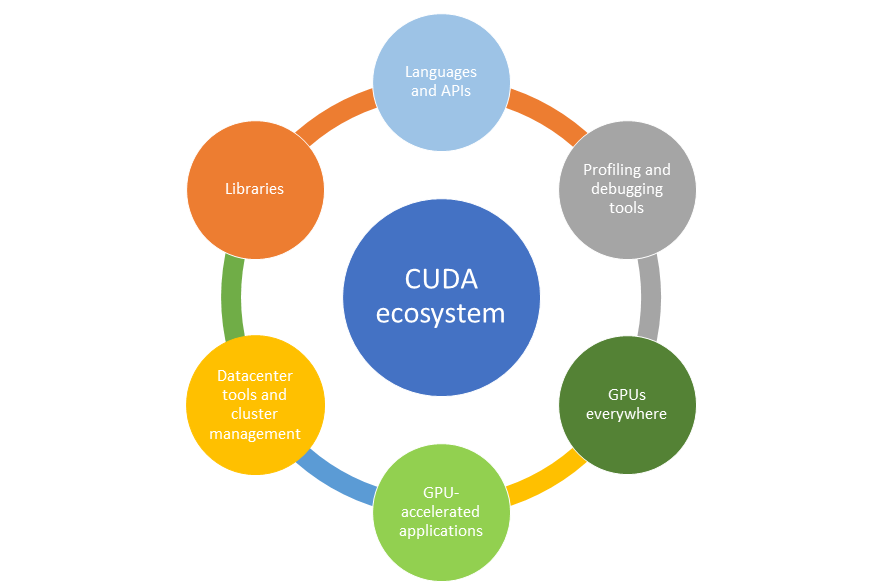
Nvidia's other strength is CUDA, a software platform that allows customers to fine tune the performance of its processors. Nvidia has been investing in this software since the mid-2000s, and has long encouraged developers to use it to build and test AI applications. This has made CUDA the de facto industry standard.
Why GPU is best for AI : While the GPU handles more difficult mathematical and geometric computations. This means GPU can provide superior performance for AI training and inference while also benefiting from a wide range of accelerated computing workloads.
Which GPU does OpenAI use
Many prominent AI companies, including OpenAI, have relied on Nvidia's GPUs to provide the immense computational power that's required to train large language models (LLMs).
Which GPU is best for AI : 5 Best GPUs for AI and Deep Learning in 2024
So, even if other big tech players continue their chip development efforts, Nvidia is likely to remain the top AI chip player for quite some time. Japanese investment bank Mizuho estimates that Nvidia could sell $280 billion worth of AI chips in 2027 as it projects the overall market hitting $400 billion.

Nvidia V100 GPUs
Since GPT-3 is a very large model with 175 billion parameters, it requires very high resources in training. According to this article it takes around 1,024 Nvidia V100 GPUs to train the model, and it costs around $4.6M and 34 days to train the GPT-3 model.
Is ChatGPT using Nvidia
It was developed by NVIDIA and Microsoft Azure, in collaboration with OpenAI, to host ChatGPT and other large language models (LLMs) at any scale.Once Nvidia realised that its accelerators were highly efficient at training AI models, it focused on optimising them for that market. Its chips have kept pace with ever more complex AI models: in the decade to 2023 Nvidia increased the speed of its computations 1,000-fold.700 gigabytes
GPT-3 requires 700 gigabytes of GPU RAM. I'm looking at my cheapest computer components retailer listing a 48 gigabyte GPU at $5k. So to run the previous generation of GPT would cost me about $70k right now.

Many prominent AI companies, including OpenAI, have relied on Nvidia's GPUs to provide the immense computational power that's required to train large language models (LLMs). (OpenAI CEO Sam Altman has teased the idea of starting his own GPU manufacturing operation, citing scarcity concerns.)
Does ChatGPT use CUDA : In real-world applications like ChatGPT, deep learning frameworks like PyTorch handle the intricacies of CUDA, making it accessible to developers without needing to write CUDA code directly.
How many GPUs does GPT 4 use : For inference, GPT-4: Runs on clusters of 128 A100 GPUs. Leverages multiple forms of parallelism to distribute processing.
How many GPUs do I need for GPT-3
Achieving GPT3 finetuning with as few as 2 NVIDIA A100 GPUs
By solving the challenges revealed above, we have successfully finetuned a GPT3-sized BLOOMZ model with 176B parameters (termed as OCRL-BLOOM) with as few as 2 NVIDIA A100 GPUs (40GB) to achieve a finetuning speed of 3.9 tokens/sec/GPU.
Training 100 Trillion Parameters
The creation of GPT-3 was a marvelous feat of engineering. The training was done on 1024 GPUs, took 34 days, and cost $4.6M in compute alone [1]. Training a 100T parameter model on the same data, using 10000 GPUs, would take 53 Years.The company's graphics processing units (GPUs) and other chips have experienced skyrocketing demand because those products are especially well suited to make demanding applications like ChatGPT run, and ChatGPT's own success has showcased the power of Nvidia's GPUs.
Does Tesla use CUDA : Its products began using GPUs from the G80 series, and have continued to accompany the release of new chips. They are programmable using the CUDA or OpenCL APIs.