If two different object instances have exactly the same data values, then the hashcode should be the same. They work by having a one-way function that maps all the values to a number.The GetHashCode method provides a hash code for algorithms that need quick checks of object equality. A hash code is a numeric value that is used to insert and identify an object in a hash-based collection, such as the Dictionary<TKey,TValue> class, the Hashtable class, or a type derived from the DictionaryBase class.The hashCode() method returns an int. There are 4,294,967,296 different possible int values. There is an object called Long, which has 18,446,744,073,709,551,616 different possible values. Based on this alone, the pigeonhole principle tells us that hashCode() values cannot possibly be unique.
Can hashCode change : The general contract of hashCode() method is: Multiple invocations of hashCode() should return the same integer value, unless the object property is modified that is being used in the equals() method. An object hash code value can change in multiple executions of the same application.
Is hashCode unique
A hash code (MD5, SHA-1, SHA-256) is of a fixed length, so it cannot be unique for all possible inputs. But all such hash functions are carefully designed to minimize the likelihood of a collision (two distinct files with the same hash value).
Are hash codes unique in C# : Hash codes are used to insert and retrieve keyed objects from hash tables efficiently. However, hash codes don't uniquely identify strings. Identical strings have equal hash codes, but the common language runtime can also assign the same hash code to different strings.
1) If two objects are equal (i.e. the equals() method returns true), they must have the same hashcode. 2) If the hashCode() method is called multiple times on the same object, it must return the same result every time. 3) Two different objects can have the same hash code. The phenomenon when two keys have same hash code is called hash collision. If hashCode() method is not implemented properly, there will be higher number of hash collision and map entries will not be properly distributed causing slowness in the get and put operations.
Is hashing always unique
Hashes are not unique. This is easy to prove: a SHA256 hash is only 256 bits long, so if you hash all the possible inputs that are 264 bits long, some of them will have to have the same hash because there aren't enough possible hashes for them to all be different. However, for all practical purposes they are unique.The general contract of hashCode() method is: Multiple invocations of hashCode() should return the same integer value, unless the object property is modified that is being used in the equals() method. An object hash code value can change in multiple executions of the same application.A hash code (MD5, SHA-1, SHA-256) is of a fixed length, so it cannot be unique for all possible inputs. But all such hash functions are carefully designed to minimize the likelihood of a collision (two distinct files with the same hash value). Hash functions must be Deterministic – meaning that every time you put in the same input, it will always create the same output. In other words, the output, or hash value, must be unique to the exact input. There should be no chance whatsoever that two different message inputs create the same output hash.
Is a hash always unique : Hashes are not unique. This is easy to prove: a SHA256 hash is only 256 bits long, so if you hash all the possible inputs that are 264 bits long, some of them will have to have the same hash because there aren't enough possible hashes for them to all be different. However, for all practical purposes they are unique.
Is hash always the same : Hash functions must be Deterministic – meaning that every time you put in the same input, it will always create the same output. In other words, the output, or hash value, must be unique to the exact input. There should be no chance whatsoever that two different message inputs create the same output hash.
Is hash always different
No matter how it is designed, the hashes of two different sequences of bytes (let's just say, “files”) can be the same. That's because the files can be of arbitrary length; whereas the hashes have a fixed length. That's just basic math… but let me illustrate with an example. Hashing is a surprisingly simple technology
And the hash value is always the same; no matter how large the file or what computer is used to compute it. The task of hashing focuses on one thing: assigning a unique value.


![Kladsko-5-malý-Karlův-Most[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Kladsko-5-maly-Karluv-Most1-1024x692-250x120.jpg)
![Stubai[1]](https://www.einarstrayorchestra.com/wp-content/uploads/2024/06/Stubai1-250x120.jpg)


Antwort Is hashCode always the same? Weitere Antworten – Does hashCode have the same value
If two different object instances have exactly the same data values, then the hashcode should be the same. They work by having a one-way function that maps all the values to a number.The GetHashCode method provides a hash code for algorithms that need quick checks of object equality. A hash code is a numeric value that is used to insert and identify an object in a hash-based collection, such as the Dictionary<TKey,TValue> class, the Hashtable class, or a type derived from the DictionaryBase class.The hashCode() method returns an int. There are 4,294,967,296 different possible int values. There is an object called Long, which has 18,446,744,073,709,551,616 different possible values. Based on this alone, the pigeonhole principle tells us that hashCode() values cannot possibly be unique.
Can hashCode change : The general contract of hashCode() method is: Multiple invocations of hashCode() should return the same integer value, unless the object property is modified that is being used in the equals() method. An object hash code value can change in multiple executions of the same application.
Is hashCode unique
A hash code (MD5, SHA-1, SHA-256) is of a fixed length, so it cannot be unique for all possible inputs. But all such hash functions are carefully designed to minimize the likelihood of a collision (two distinct files with the same hash value).
Are hash codes unique in C# : Hash codes are used to insert and retrieve keyed objects from hash tables efficiently. However, hash codes don't uniquely identify strings. Identical strings have equal hash codes, but the common language runtime can also assign the same hash code to different strings.
1) If two objects are equal (i.e. the equals() method returns true), they must have the same hashcode. 2) If the hashCode() method is called multiple times on the same object, it must return the same result every time. 3) Two different objects can have the same hash code.
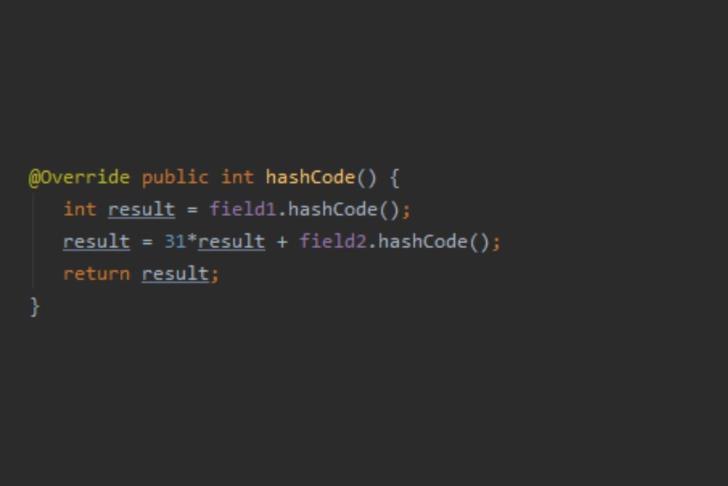
The phenomenon when two keys have same hash code is called hash collision. If hashCode() method is not implemented properly, there will be higher number of hash collision and map entries will not be properly distributed causing slowness in the get and put operations.
Is hashing always unique
Hashes are not unique. This is easy to prove: a SHA256 hash is only 256 bits long, so if you hash all the possible inputs that are 264 bits long, some of them will have to have the same hash because there aren't enough possible hashes for them to all be different. However, for all practical purposes they are unique.The general contract of hashCode() method is: Multiple invocations of hashCode() should return the same integer value, unless the object property is modified that is being used in the equals() method. An object hash code value can change in multiple executions of the same application.A hash code (MD5, SHA-1, SHA-256) is of a fixed length, so it cannot be unique for all possible inputs. But all such hash functions are carefully designed to minimize the likelihood of a collision (two distinct files with the same hash value).
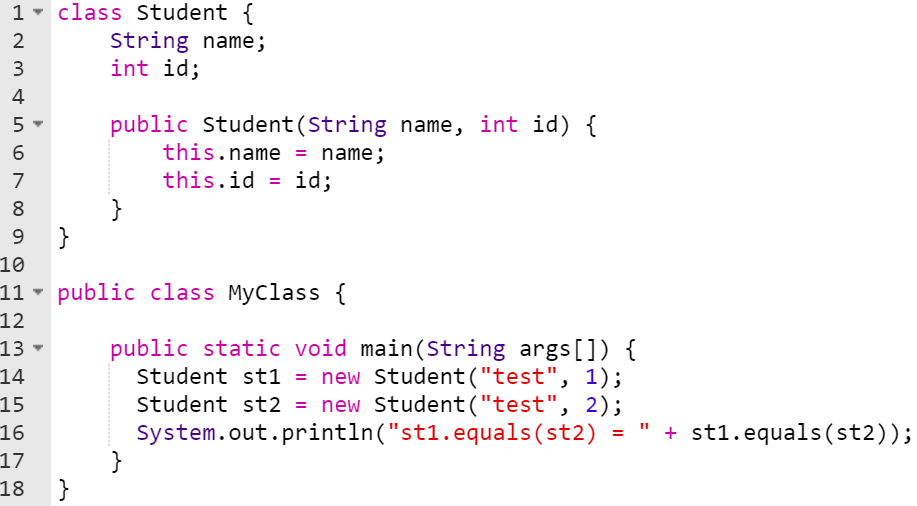
Hash functions must be Deterministic – meaning that every time you put in the same input, it will always create the same output. In other words, the output, or hash value, must be unique to the exact input. There should be no chance whatsoever that two different message inputs create the same output hash.
Is a hash always unique : Hashes are not unique. This is easy to prove: a SHA256 hash is only 256 bits long, so if you hash all the possible inputs that are 264 bits long, some of them will have to have the same hash because there aren't enough possible hashes for them to all be different. However, for all practical purposes they are unique.
Is hash always the same : Hash functions must be Deterministic – meaning that every time you put in the same input, it will always create the same output. In other words, the output, or hash value, must be unique to the exact input. There should be no chance whatsoever that two different message inputs create the same output hash.
Is hash always different
No matter how it is designed, the hashes of two different sequences of bytes (let's just say, “files”) can be the same. That's because the files can be of arbitrary length; whereas the hashes have a fixed length. That's just basic math… but let me illustrate with an example.

Hashing is a surprisingly simple technology
And the hash value is always the same; no matter how large the file or what computer is used to compute it. The task of hashing focuses on one thing: assigning a unique value.